The News of a positive
change in the character of a villain (did something very good) of your area may surprise you, but his
negative change may not. These two sides
of changes do not have an uniform impact on you. Again, think of a very moral
person you like. His negative change may shock
you but his positive change won’t. These two changes in opposite directions
(positive and negative) do not have the same power to move you, in both
examples. And the effects are not really symmetric or equivalent; they are
asymmetric or non-equivalent. Asymmetry is one type of non-linearity. The asymmetries and other other forms of non-linearity are also frequent in economic
variables. For example, an increase (positive change) in oil price is said to
have stronger effect on particular macroeconomic variables than decrease
(negative change). In fact, ‘’nonlinearity is endemic within the social
sciences and that asymmetry is fundamental to the human condition’’ Shin et
al. (2014)
A conventional time series regression model contains constant parameters
and assumes that a change in explanatory variable has the same effect over time
which may not be appropriate in all cases as shown in the oil example earlier. Again, the popular cointegration tecniques
such as EG-ECM, VECM, Bound testing etc. imply a constant speed of adjustment (
i.e a constant ECT) to long-run equilibrium after a shock (change). But this dos
not hold true always when there is market frictions. (see G Dufrénot, V Mignon 2012). Estimating a
relationship which possibly has asymmetry with symmetric techniques seems unfair
and may leads one to some serious inappropriate
policy conclusions (Enders 2014)). Since the conventiona cointeration test doesn’t
allow one to capture the asymmetries in macroeconomic variables. Various
techniques have been introduced so far to account this asymmetry, Threshold
ECM, Smooth transition regression ECM. Markov-switching ECM etc. But the recent
NARDL or Non-linear Autoregressive Model proposed by shin et al (2014) incorporate
asymmetries both in the long run and in short run relationships, and at the same time, it captures the
asymmetries in the dynamic adjustment.
Moreover, it allows the regressors of
mixed order of I(0) and I(1).
An illustration: If inflation rate
rises in a country you may expect that the domestic foods becomes expensive and there will be a
tendency to import foods from foreign countries. The relationship is positive. Again if inflation rate falls the consumers find domestic foods cheaper and
people reduce buying foreign foods, the food imports decline (positive
relationship). Although in both cases the food imports react positively to the
inflation rate, are the magnitudes of reactions same in both cases ? maybe not; maybe food import response more to positive change or otherwise. A time series regression specification with a constant parameter will tell us that the reaction is same in both direction. Here comes the NARDL. NARDL (also other asymmetric regression techniques) explicitly distinguishes the reactions of both directions.
I denote food import by foodt and inflation rate by INFt, intercept by C and residuals by Ut. For simplicity, ignore the other regressors that may influence the food import. The simple OLS two-variable model takes the following form:
I denote food import by foodt and inflation rate by INFt, intercept by C and residuals by Ut. For simplicity, ignore the other regressors that may influence the food import. The simple OLS two-variable model takes the following form:
Foodt=C+βINFt
+ Ut.
|
To capture the possible
asymmetric effects of inflation on food import NARDL technique decomposes the inflation rate series into two parts 1)partial sum of positive
change in inflation rate denoted by INFt+ and 2) partial sum of positive change
in inflation rate denoted by INFt- and include both of them as separate regressors in the model and the model becomes:
Foodt=C+β1 INFt+ + β2
INFt - + Ut.
|
Clearly, this is now a three-variable OLS model.
If we now represent this equation in (linear) ARDL model proposed by pesaran et. Al (2001) the final model takes the form as show in picture below. The model shown in the picture is the general form of NARDL. (Non linear Autoregressive Distributed Lag Model. See the explanation of each term in the picture below.
If we now represent this equation in (linear) ARDL model proposed by pesaran et. Al (2001) the final model takes the form as show in picture below. The model shown in the picture is the general form of NARDL. (Non linear Autoregressive Distributed Lag Model. See the explanation of each term in the picture below.

🔍The long run coefficients: We can calculate the long run
coefficient of INF+t by dividing the the negative of the
coefficient of INF+t , θ+ by
the coefficient of Foodt-1 , ρ, and the
the long run coefficient of INF- t by dividing the negative of the coefficient
of INF-t , θ- by the coefficient of Foodt-1
, ρ
(-θ+ /
ρ) and (-θ- / ρ) are the long run coefficients of of INFt+
and INFt- , respectively.
The summation notation Σ implies that
NARDL consider inclusion of differenced variables into model upto some lags. For
example, in case of ∆Foodt-1, NARDL
considers the incusion of its first
lagged term upto maximum lag you choose, if appropriate. And in case of ∆INF-t it consider the the
inclusion of its zero lag (∆INF-t itself) upto the maximum lag you choose,
if appropriate.
🔍Asymmetric Cointegration test: A long run relationship or cointegration is present if the joint null hypothesis,
ρ =θ+ = θ- =zero is rejected. The critical value are the same critical values for ARDL.
🔍Testing Symmetry: Clearly, if the long-run coefficients (-θ+ / ρ) and (-θ- / ρ) are not same then there is asymmetry in the long run. So we test the null hypothesis of (-θ+ / ρ) = (-θ- / ρ). If the null is rejected then there is an evidence of long-run asymmetry in the model.
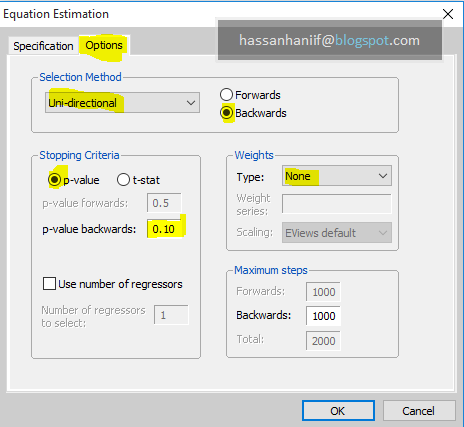
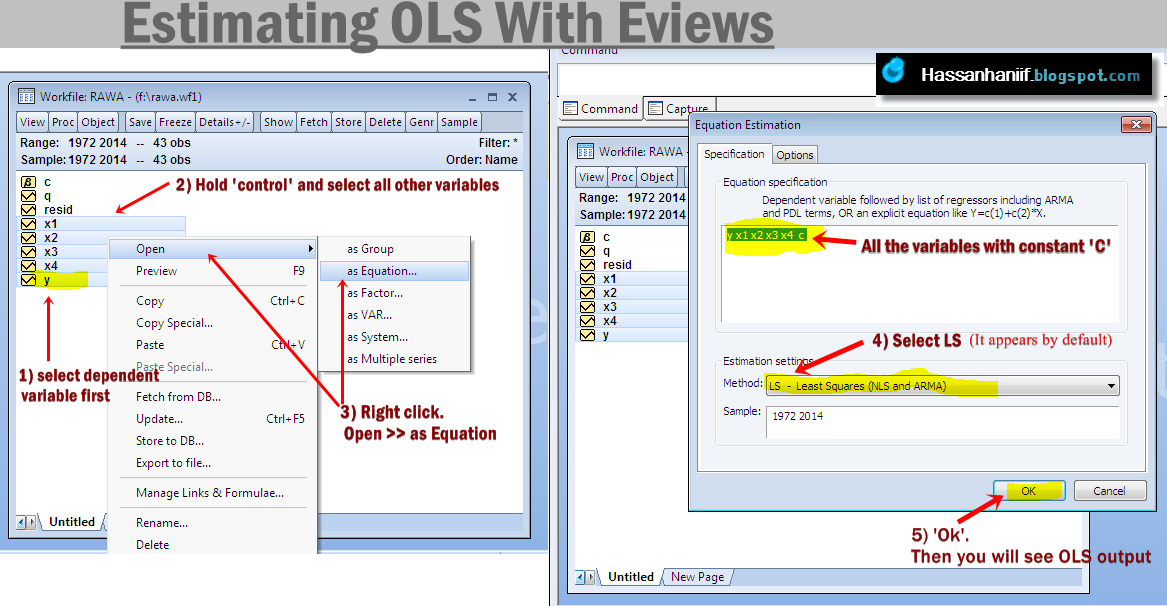
To estimate NARDL, follow these steps:
See my another post on estimating Nonlinear ARDL (NARDL) with Eviews.
To estimate NARDL, follow these steps:
Steps:
F
F
Step 1. Perform unit root tests to justify that non of the variables are I(2).
|
Step 2. Generate INFt+ and INFt– from INFt
|
Step 3. Run the Non linear ECM under NARDL
|
Step 4. Test the ‘non linear cointegration’ test with F-test
|
Step 5. check the asymmetries.
|
See my another post on estimating Nonlinear ARDL (NARDL) with Eviews.
NARDL With Eviews
Shin et al. (2104):
Researchgate link
https://www.researchgate.net/publication/228275564_Modelling_Asymmetric_Cointegration_and_Dynamic_Multipliers_in_a_Nonlinear_ARDL_Framework
Some papers which applied NARDL:
1. Abdlaziz, Rizgar Abdlkarim, Khalid Abdul Rahim, and Peter Adamu. "Oil and Food Prices Co-integration Nexus for Indonesia: A Nonlinear ARDL Analysis." International Journal of Energy Economics and Policy 6.1 (2016).
2. Ndoricimpa, Arcade. "Analysis of asymmetries in the nexus among energy use, pollution emissions and real output in South Africa." Energy (2017).
3. Zhang, Zan, Su-Ling Tsai, and Tsangyao Chang. "New Evidence of Interest Rate Pass-through in Taiwan: A Nonlinear Autoregressive Distributed Lag Model." Global Economic Review (2017): 1-14.
References:
- Dufrénot, Gilles, and Valérie Mignon. Recent developments in nonlinear cointegration with applications to macroeconomics and finance. Springer Science & Business Media, 2012. link
- Enders, Walter. Applied Econometric Time Series. Hoboken: Wiley, 2015. Print.
- Pesaran, M. Hashem, Yongcheol Shin, and Richard J. Smith. "Bounds testing approaches to the analysis of level relationships." Journal of applied econometrics 16.3 (2001): 289-326. link
- Shin, Y., Yu, B., Greenwood-Nimmo, M.J., 2014. Modelling Asymmetric Cointegration and Dynamic Multipliers in a Nonlinear ARDL Framework. In William C. Horrace and Robin C. Sickles (Eds.), Festschrift in Honor of Peter Schmidt: Econometric Methods and Application, pp. 281-314. New York (NY): Springer Science & Business Media. link
Eviews official website: